raw.sh
Batched reward model inference and Best-of-N sampling
Reward models have been a key part of reinforcement learning on top of LLMs, used broadly in techniques like RLHF and as LLM-as-a-judge critics in evals. They have also been used in the data preparation phase of preference optimization methods like SimPO, where a reward model is used to create the preference data used to train models like princeton-nlp/gemma-2-9b-it-SimPO.
I recently had some trouble figuring out how to run high throughput reward model inference. Offline, you can just collect everything you need to score in advance and go through all of your data in batches. But for a lot of use cases, such as for search methods like tree search or MCTS, this is hard to do efficiently. Unfortunately, easy to set up inference servers like vLLM and llama.cpp don't support sequence classification1 / reward models out of the box (yet2)
Dynamic batching with batched
Thankfully, Mixedbread has a great generic dynamic batching library that makes it really easy to inference reward models3.
Here's how we can host an endpoint on Modal4. First, let's add some helper functions and setup the image:
I'm using RLHFlow/ArmoRM-Llama3-8B-v0.1, the same reward model used by the SimPO team, which uses Mixture-of-Experts aggregation of reward objectives with each expert corresponding to a human-interpretable objective (such as helpfulness, safety, coherence...)
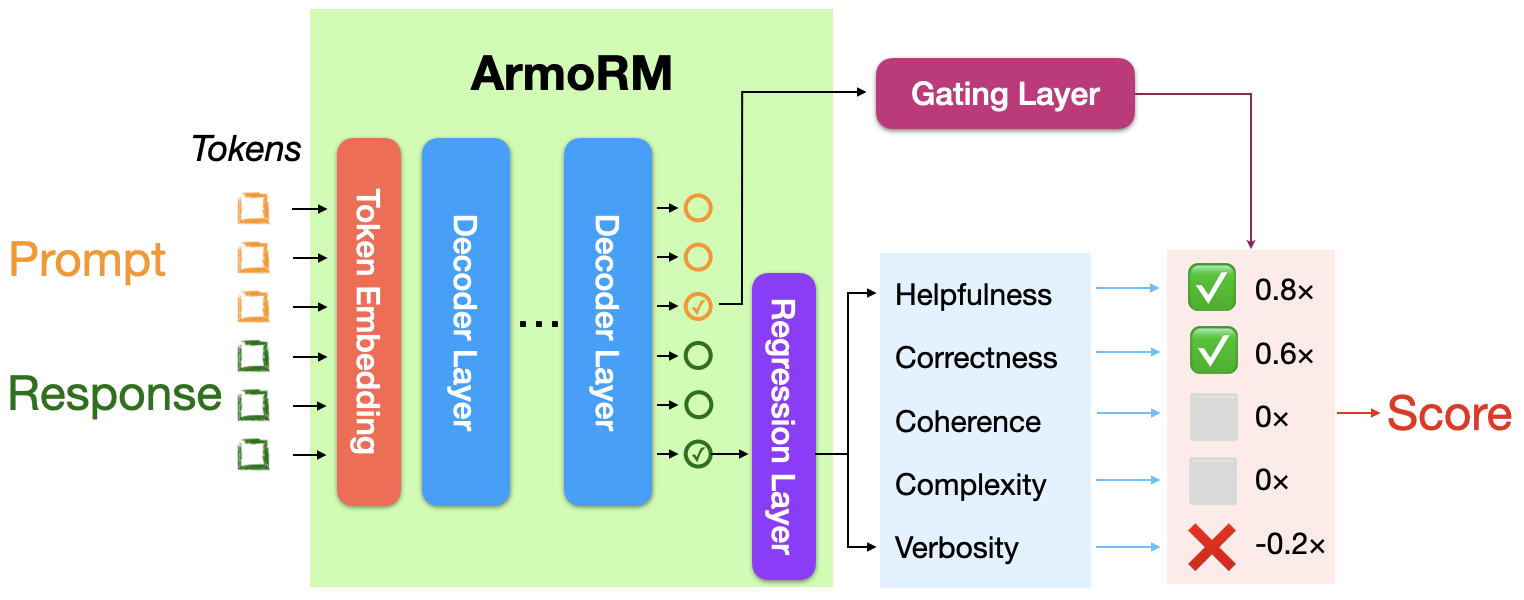
Check out the blog post from RLHFlow for more details5.
Now we can add the meat of the code, a web endpoint to score a LLM completion using dynamic batching under the hood.
The allow_concurrent_inputs setting prevents Modal from starting multiple servers so we can take advantage of dynamic batching. Now we can use this reward model endpoint with a hosted API or an open source model + vLLM.
Evaluating the reward model
Since my cloud GPU bill this month is kind of ridiculous, I decided to evaluate using a small random 100 question subset of TruthfulQA, a multiple choice benchmark for LLMs.
One way to benchmark the reward model on multiple choice data is to check the score for each possible answer to the question6. Here are the results:
The reward model scores the correct answer the highest 53% of the time. Next we will evaluate Best-of-N sampling, choosing the best LLM completion using the reward model.
Best-of-N-Sampling
Now we can test LLM + reward model verifier, a super simple way to add more test time compute. Inference time scaling with Best-of-N-Sampling doesn't add much latency (we can sample and score hundreds of completions in parallel with batching) and is super easy to implement7.
I get the following zero-shot accuracy with Llama-3.1-8B-Instruct:
| # completions | 1 | 2 | 4 | 8 | 16 | 32 | 64 |
|---|---|---|---|---|---|---|---|
| accuracy (%) | 58 | 63 | 64 | 63 | 70 | 67 | 67 |
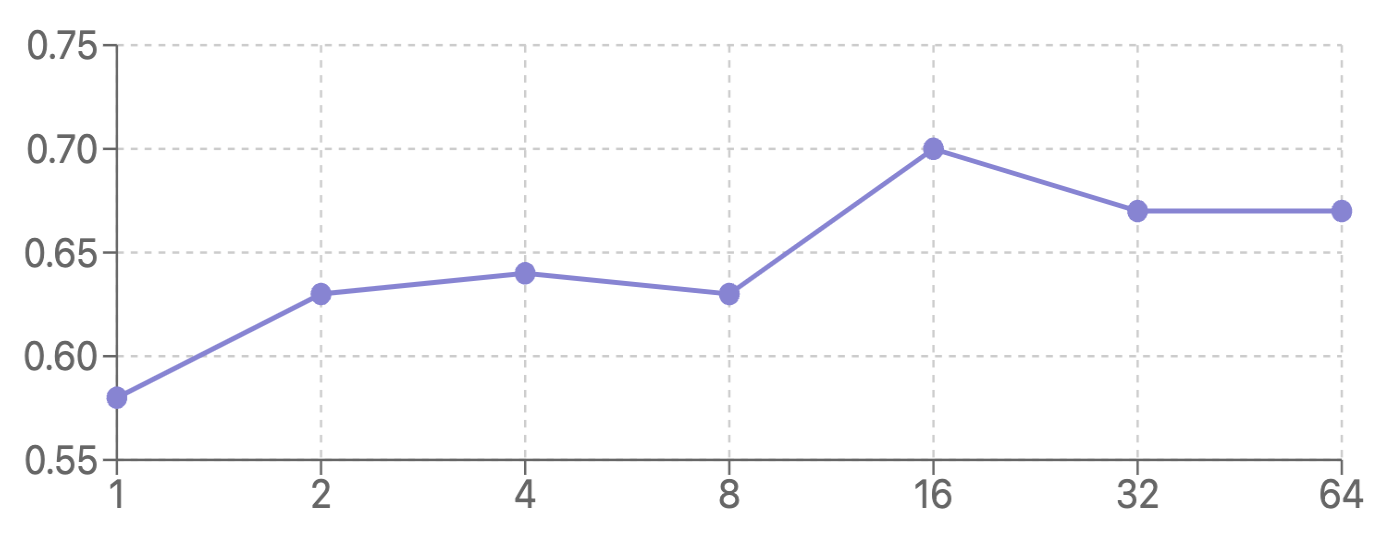
note: log scale
Using the reward model with Best-of-N-Sampling shows a 20.7% increase in accuracy from n=1 to n=16, with performance plateauing with more than 16 generations.
Footnotes
-
Reward models often use architectures similar to
SequenceClassification, but output a single scalar rather than multiple class outputs. ↩ -
vLLM supports Qwen2.5-Math-RM-72B (see the model implementation), but reward model API is still on the roadmap. ↩
-
Not sponsored, I just really like the development workflow. To deploy this on your own machine you can swap out the Modal code for a local Flask server. ↩
-
RLHFlow has a lot of great resources. Also check out RLHFlow/RLHF-Reward-Modeling for reward model training recipes. ↩
-
Reward model benchmark code: eval_reward.py. Note that evaluating answers directly is "harder" than evaluating model completions, since we aren't providing any chain-of-thought data to the reward model, just the final answer. ↩
-
Best-of-N-Sampling benchmark code: best_of_n.py ↩