Turns out GPT completion models are pretty good at chess, with gpt-3.5-turbo-instruct playing around 1800 elo1. However, chat models typically struggle.
It's been shown that combining fine-tuning and prompt optimization can be powerful2. To see if the performance of chat models could be brought up to a level competitive with completion models, I ran several experiments.
I tried automatically optimizing the LLM chess puzzle solving prompt with tuned few shot examples using DSPy. Additionally, in light of OpenAI's 2 million tokens of free finetuning per day, I also tried finetuning gpt-4o-mini on the optimized LLM chain of thought outputs from gpt-4o.
Glossary
Finetuning: The process of further training a pre-trained language model on a specific dataset to improve its performance on a particular task.Prompt optimization: The technique of refining and improving the input prompts given to an AI model to elicit better and more accurate responses.Few shot prompting: A method where a language model is given a small number of examples (usually 2-5) within the prompt to help it understand and perform a specific task.Chain of thought (CoT): An approach that encourages AI models to break down complex problems into step-by-step reasoning, often by including intermediate steps in prompts or training data.DSPy: Very good™️ framework for algorithmically optimizing LM prompts and weights.
Contents
Dataset
To create a dataset to evaluate the models on, I used puzzles from the lichess database3, which provides a dataset of 4 million chess puzzles with metadata. For each chess puzzle, I called the API to get the full list of moves in PGN format, with one example for each move of the puzzle.
PGN: 1. e3 e5 2. Ne2 d5 3. Ng3 Nf6 4. Nh5 Bd6 5. d3 Bg4 6.
Answer: ?
PGN: 1. e3 e5 2. Ne2 d5 3. Ng3 Nf6 4. Nh5 Bd6 5. d3 Bg4 6.
Answer: ?
solution (hint: knight move)4
The processed dataset is available on huggingface.
Can completion models solve chess puzzles?
GPT completion models provide a strong baseline, with babbage and davinci getting 61.23% and 74.45% accuracy on the evaluation set respectively.
Completion models baseline
| Model | Accuracy |
|---|
| babbage-002 | 61.23% |
| davinci-002 | 74.45% |
Promptization
Without showing the LLM any examples, chat model performance is pretty poor, with gpt-4o-mini only solving 17.4% of puzzles, and gpt-4o solving 28.44%.
DSPy Program
DSPy: The framework for programming—not prompting—foundation models
To optimize our program with DSPy, we can express it using an LLM signature and module. This simple signature will be optimized into high-quality prompts with few shot examples.
class ChessSolver(dspy.Signature):
"""Given a series of chess moves in Portable Game Notation (PGN) format, your task is to determine and return the correct next move in Standard Algebraic Notation (SAN) format."""
pgn = dspy.InputField(desc="The chess position")
answer = dspy.OutputField(desc="The correct next move in SAN format")
class ChessEngine(dspy.Module):
def __init__(self):
super().__init__()
self.generate_move = dspy.ChainOfThought(ChessSolver)
def forward(self,pgn):
gen_pred = self.generate_move(pgn=pgn)
gen_move = gen_pred.answer
gen_move = gen_move.split(" ")[-1]
valid, reason = validate_pgn_move(pgn, gen_move)
dspy.Suggest(valid, reason)
if valid:
print(f"valid:\n{pgn} *{gen_move}")
if not valid:
print(f"invalid:\n{pgn} *{gen_move}*\n{reason}")
return dspy.Prediction(pgn=pgn, answer=gen_move, rationale=gen_pred.rationale)
class ChessSolver(dspy.Signature):
"""Given a series of chess moves in Portable Game Notation (PGN) format, your task is to determine and return the correct next move in Standard Algebraic Notation (SAN) format."""
pgn = dspy.InputField(desc="The chess position")
answer = dspy.OutputField(desc="The correct next move in SAN format")
class ChessEngine(dspy.Module):
def __init__(self):
super().__init__()
self.generate_move = dspy.ChainOfThought(ChessSolver)
def forward(self,pgn):
gen_pred = self.generate_move(pgn=pgn)
gen_move = gen_pred.answer
gen_move = gen_move.split(" ")[-1]
valid, reason = validate_pgn_move(pgn, gen_move)
dspy.Suggest(valid, reason)
if valid:
print(f"valid:\n{pgn} *{gen_move}")
if not valid:
print(f"invalid:\n{pgn} *{gen_move}*\n{reason}")
return dspy.Prediction(pgn=pgn, answer=gen_move, rationale=gen_pred.rationale)
Check if moves are valid:
def validate_pgn_move(pgn_board, san_move):
# Create a board from the PGN
board = chess.Board()
pgn = io.StringIO(pgn_board)
game = chess.pgn.read_game(pgn)
# Apply all moves from the PGN to get the current board state
for move in game.mainline_moves():
board.push(move)
# Parse the new move
try:
print(str(san_move))
chess_move = board.parse_san(str(san_move))
except chess.InvalidMoveError:
return False, "Invalid move notation"
except chess.IllegalMoveError:
return False, "Illegal move"
except chess.AmbiguousMoveError:
return False, "SAN is ambigious"
# Check if the move is legal
if chess_move in board.legal_moves:
return True, "Move is valid"
else:
return False, "Move is not legal in the current position"
def validate_pgn_move(pgn_board, san_move):
# Create a board from the PGN
board = chess.Board()
pgn = io.StringIO(pgn_board)
game = chess.pgn.read_game(pgn)
# Apply all moves from the PGN to get the current board state
for move in game.mainline_moves():
board.push(move)
# Parse the new move
try:
print(str(san_move))
chess_move = board.parse_san(str(san_move))
except chess.InvalidMoveError:
return False, "Invalid move notation"
except chess.IllegalMoveError:
return False, "Illegal move"
except chess.AmbiguousMoveError:
return False, "SAN is ambigious"
# Check if the move is legal
if chess_move in board.legal_moves:
return True, "Move is valid"
else:
return False, "Move is not legal in the current position"
By optimizing over few shot examples with DSPy, gpt-4o-mini performance is boosted from 17.4% to 25.99%, a 50% increase. When combined with a self-correction step for illegal moves and 2 retries, the accuracy further improves to 31.72%.
This is pretty cheap to run with gpt4o-mini, and the performance of a prompt compiled with a small model usually transfers well to a larger model in the same family. Using the newly optimized few shot chain of thought prompt with gpt-4o brings some impressive gains, bringing the accuracy up to 63.88%.
Compiling
Using the DSPy MIPROv2 optimizer:
# Define hyperparameters:
N = 20 # The number of instructions and fewshot examples that we will generate and optimize over
batches = 50 # The number of optimization trials to be run (we will test out a new combination of instructions and fewshot examples in each trial)
temperature = 1.0 # The temperature configured for generating new instructions
# Set up metrics
NUM_THREADS = 64
# Eval
metric = dspy.evaluate.answer_exact_match
kwargs = dict(num_threads=NUM_THREADS, display_progress=True)
evaluate = Evaluate(devset=val, metric=metric, **kwargs)
# baseline
baseline_val_score = evaluate(program_with_assertions, devset=val)
print(f"Baseline val: {baseline_val_score}")
# compile
eval_kwargs = dict(num_threads=NUM_THREADS, display_progress=True, display_table=0)
teleprompter = MIPROv2(prompt_model=prompt_model, task_model=task_model, metric=metric, num_candidates=N, init_temperature=temperature, verbose=True)
compiled_program = teleprompter.compile(program_with_assertions, trainset=train, valset=val, num_batches=batches, max_bootstrapped_demos=3,max_labeled_demos=5, eval_kwargs=eval_kwargs)
compiled_program.save("compiled_chess_cot_ft_student.dspy")
# compiled score
fs_val_score, fs_outputs = evaluate(compiled_program, devset=val, return_outputs=True)
print(f"Few shot compiled val: {fs_val_score}")
# Define hyperparameters:
N = 20 # The number of instructions and fewshot examples that we will generate and optimize over
batches = 50 # The number of optimization trials to be run (we will test out a new combination of instructions and fewshot examples in each trial)
temperature = 1.0 # The temperature configured for generating new instructions
# Set up metrics
NUM_THREADS = 64
# Eval
metric = dspy.evaluate.answer_exact_match
kwargs = dict(num_threads=NUM_THREADS, display_progress=True)
evaluate = Evaluate(devset=val, metric=metric, **kwargs)
# baseline
baseline_val_score = evaluate(program_with_assertions, devset=val)
print(f"Baseline val: {baseline_val_score}")
# compile
eval_kwargs = dict(num_threads=NUM_THREADS, display_progress=True, display_table=0)
teleprompter = MIPROv2(prompt_model=prompt_model, task_model=task_model, metric=metric, num_candidates=N, init_temperature=temperature, verbose=True)
compiled_program = teleprompter.compile(program_with_assertions, trainset=train, valset=val, num_batches=batches, max_bootstrapped_demos=3,max_labeled_demos=5, eval_kwargs=eval_kwargs)
compiled_program.save("compiled_chess_cot_ft_student.dspy")
# compiled score
fs_val_score, fs_outputs = evaluate(compiled_program, devset=val, return_outputs=True)
print(f"Few shot compiled val: {fs_val_score}")
A few million tokens later...
Compiled prompt
DSPy optimized chain of thought prompt with 5 few shot examples:
{
"generate_move": {
"lm": null,
"traces": [],
"train": [],
"demos": [
{
"augmented": true,
"pgn": "1. e4 e5 2. Ne2 Bc5 3. Ng3 d6 4. Bc4 h6 5. O-O Nf6 6. d3 O-O 7. Nh5 Bg4 8. Nxf6+ Qxf6 9. ",
"rationale": "Pgn: 1. e4 e5 2. Ne2 Bc5 3. Ng3 d6 4. Bc4 h6 5. O-O Nf6 6. d3 O-O 7. Nh5 Bg4 8. Nxf6+ Qxf6 9.\nReasoning: Let's think step by step in order to determine the best move for White. After 8...Qxf6, Black has captured the knight on f6, and now White needs to respond. The most logical move for White is to play 9. Qxg4, capturing the bishop on g4. This move not only gains material but also puts pressure on Black's position.",
"move": "Qxg4"
},
{
"augmented": true,
"pgn": "1. e4 d5 2. exd5 Qxd5 3. Nc3 Qd8 4. Nf3 Nf6 5. h3 Bf5 6. Bc4 e6 7. d3 Be7 8. Qe2 O-O 9. Bd2 a6 10. g4 Bg6 11. Ne5 b5 12. Bb3 c5 13. h4 h6 14. Nxg6 fxg6 15. g5 Nd5 16. Nxd5 exd5 17. Qe6+ Kh7 18. Bxd5 Bxg5 19. O-O-O Bxd2+ 20. Rxd2 Rf6 21. Qe4 Ra7 22. h5 Re7 23. hxg6+ Kh8 24. Qg2 Qd6 25. Re2 Rxe2 26. Rxh6+ gxh6 27. g7+ Kh7 28. ",
"rationale": "determine the best move for White. The position after 28. is critical as White has a strong initiative and is threatening to deliver checkmate or win material. The last move played by Black was 27...Kh7, which puts the Black king in a precarious position. \n\nWhite has several options to consider, but the most effective move is to play 29. g8=Q+. This move promotes the pawn on g7 to a queen, delivering check to the Black king. The newly promoted queen will also create a significant threat, as it can potentially lead to checkmate on the next move if Black does not respond adequately.",
"move": "g8=Q+"
},
{
"pgn": "1. e4 e5 2. Nf3 Nc6 3. Bc4 Bc5 4. c3 Nf6 5. d4 exd4 6. cxd4 Bb4+ 7. Nc3 Nxe4 8. O-O Bxc3 9. d5 Bf6 10. Re1 Ne7 11. Rxe4 d6 12. Bg5 Bxg5 13. Nxg5 h6 14. Nf3 O-O 15. Qe2 Ng6 16. Re1 Bf5 17. Rd4 a6 18. Bd3 Bxd3 19. Qxd3 Qd7 20. h4 Rae8 21. Rxe8 Rxe8 22. h5 Ne5 23. Nxe5 Rxe5 24. g4 Qe7 25. Kg2 Re1 26. Qf5 g6 27. hxg6 fxg6 28. Qxg6+ Qg7 29. Qxg7+ Kxg7 30. Rd2 Kf6 31. f4 Re4 32. Kf3 Rc4 33. b3 Rc5 34. Ke4 Ra5 35. a4 Rc5 36. Rd3 Rc1 37. Rh3 Kg6 38. f5+ Kg5 39. Kf3 Rc3+ 40. Kg2",
"answer": "Rxh3"
},
{
"pgn": "1. e4 e5 2. f4 exf4 3. Bc4 d6 4. Nc3 h6 5. d4 g5 6. h4 Bg7 7. hxg5 hxg5 8. Rxh8 Bxh8 9. Qh5 Qf6 10. Nd5 Qxd4 11. Nxc7+ Kd8 12. Nf3 Qxe4+ 13. Be2 Kxc7 14. Qxh8 Ne7 15. Nxg5 Qxg2 16. Bxf4 Bg4 17. O-O-O Qxe2 18. Bxd6+ Kb6 19. Qd4+ Kc6 20.",
"answer": "Qc3+"
},
{
"pgn": "1. e4 e5 2. d3 Nc6 3. Be2 d5 4. exd5 Qxd5 5. Bf3 Qd8 6. Bxc6+ bxc6 7. Nf3 Bd6 8. O-O h6 9. Qe2 Qf6 10. d4 Bg4 11. dxe5 Bxf3 12. exf6+ Bxe2 13. Re1 Nxf6 14. Rxe2+ Be7 15. b3 O-O-O 16. Rxe7",
"answer": "Rd1+"
}
],
"signature_instructions": "Given a sequence of chess moves in Portable Game Notation (PGN) format, critically analyze the current board position to determine the next optimal move in Standard Algebraic Notation (SAN) format. Your answer should include a detailed step-by-step reasoning to justify why this move is the best choice, considering the current threats, opportunities for material gain, and positional advantages. Ensure that your rationale explains how your chosen move aligns with an overall strategic plan to improve your position and counter your opponent's threats.",
"signature_prefix": "Move:"
}
}
{
"generate_move": {
"lm": null,
"traces": [],
"train": [],
"demos": [
{
"augmented": true,
"pgn": "1. e4 e5 2. Ne2 Bc5 3. Ng3 d6 4. Bc4 h6 5. O-O Nf6 6. d3 O-O 7. Nh5 Bg4 8. Nxf6+ Qxf6 9. ",
"rationale": "Pgn: 1. e4 e5 2. Ne2 Bc5 3. Ng3 d6 4. Bc4 h6 5. O-O Nf6 6. d3 O-O 7. Nh5 Bg4 8. Nxf6+ Qxf6 9.\nReasoning: Let's think step by step in order to determine the best move for White. After 8...Qxf6, Black has captured the knight on f6, and now White needs to respond. The most logical move for White is to play 9. Qxg4, capturing the bishop on g4. This move not only gains material but also puts pressure on Black's position.",
"move": "Qxg4"
},
{
"augmented": true,
"pgn": "1. e4 d5 2. exd5 Qxd5 3. Nc3 Qd8 4. Nf3 Nf6 5. h3 Bf5 6. Bc4 e6 7. d3 Be7 8. Qe2 O-O 9. Bd2 a6 10. g4 Bg6 11. Ne5 b5 12. Bb3 c5 13. h4 h6 14. Nxg6 fxg6 15. g5 Nd5 16. Nxd5 exd5 17. Qe6+ Kh7 18. Bxd5 Bxg5 19. O-O-O Bxd2+ 20. Rxd2 Rf6 21. Qe4 Ra7 22. h5 Re7 23. hxg6+ Kh8 24. Qg2 Qd6 25. Re2 Rxe2 26. Rxh6+ gxh6 27. g7+ Kh7 28. ",
"rationale": "determine the best move for White. The position after 28. is critical as White has a strong initiative and is threatening to deliver checkmate or win material. The last move played by Black was 27...Kh7, which puts the Black king in a precarious position. \n\nWhite has several options to consider, but the most effective move is to play 29. g8=Q+. This move promotes the pawn on g7 to a queen, delivering check to the Black king. The newly promoted queen will also create a significant threat, as it can potentially lead to checkmate on the next move if Black does not respond adequately.",
"move": "g8=Q+"
},
{
"pgn": "1. e4 e5 2. Nf3 Nc6 3. Bc4 Bc5 4. c3 Nf6 5. d4 exd4 6. cxd4 Bb4+ 7. Nc3 Nxe4 8. O-O Bxc3 9. d5 Bf6 10. Re1 Ne7 11. Rxe4 d6 12. Bg5 Bxg5 13. Nxg5 h6 14. Nf3 O-O 15. Qe2 Ng6 16. Re1 Bf5 17. Rd4 a6 18. Bd3 Bxd3 19. Qxd3 Qd7 20. h4 Rae8 21. Rxe8 Rxe8 22. h5 Ne5 23. Nxe5 Rxe5 24. g4 Qe7 25. Kg2 Re1 26. Qf5 g6 27. hxg6 fxg6 28. Qxg6+ Qg7 29. Qxg7+ Kxg7 30. Rd2 Kf6 31. f4 Re4 32. Kf3 Rc4 33. b3 Rc5 34. Ke4 Ra5 35. a4 Rc5 36. Rd3 Rc1 37. Rh3 Kg6 38. f5+ Kg5 39. Kf3 Rc3+ 40. Kg2",
"answer": "Rxh3"
},
{
"pgn": "1. e4 e5 2. f4 exf4 3. Bc4 d6 4. Nc3 h6 5. d4 g5 6. h4 Bg7 7. hxg5 hxg5 8. Rxh8 Bxh8 9. Qh5 Qf6 10. Nd5 Qxd4 11. Nxc7+ Kd8 12. Nf3 Qxe4+ 13. Be2 Kxc7 14. Qxh8 Ne7 15. Nxg5 Qxg2 16. Bxf4 Bg4 17. O-O-O Qxe2 18. Bxd6+ Kb6 19. Qd4+ Kc6 20.",
"answer": "Qc3+"
},
{
"pgn": "1. e4 e5 2. d3 Nc6 3. Be2 d5 4. exd5 Qxd5 5. Bf3 Qd8 6. Bxc6+ bxc6 7. Nf3 Bd6 8. O-O h6 9. Qe2 Qf6 10. d4 Bg4 11. dxe5 Bxf3 12. exf6+ Bxe2 13. Re1 Nxf6 14. Rxe2+ Be7 15. b3 O-O-O 16. Rxe7",
"answer": "Rd1+"
}
],
"signature_instructions": "Given a sequence of chess moves in Portable Game Notation (PGN) format, critically analyze the current board position to determine the next optimal move in Standard Algebraic Notation (SAN) format. Your answer should include a detailed step-by-step reasoning to justify why this move is the best choice, considering the current threats, opportunities for material gain, and positional advantages. Ensure that your rationale explains how your chosen move aligns with an overall strategic plan to improve your position and counter your opponent's threats.",
"signature_prefix": "Move:"
}
}
Interestingly, the rationale in the first example has a bug, and repeats the PGN from the instructions. Removing this actually drops the performance significantly.
DSPy Compiled Results
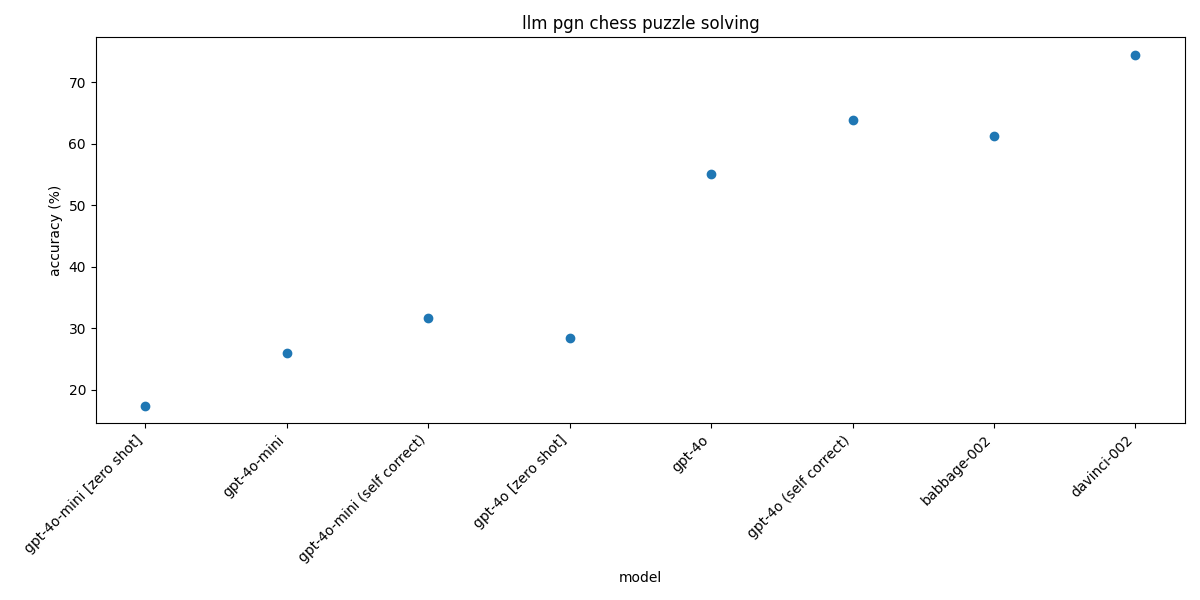
Chat models + DSPy
| Model | Accuracy |
|---|
| gpt-4o-mini [zero shot] | 17.4% |
| gpt-4o-mini | 25.99% |
| gpt-4o-mini [SELF CORRECT 3 tries max] | 31.72% |
| gpt-4o [zero shot] | 28.44% |
| gpt-4o | 55.07% |
| gpt-4o [SELF CORRECT 3 tries max] | 63.88% |
Finetuning
Constructing good examples
By running the best pipeline we have available (gpt-4o with the compiled prompt), we can construct fine tuning examples with the chain of thought processes from a strong model.
gpt-4o-mini
The resulting finetuned gpt-4o-mini model gets 65.64% accuracy, a 280% improvement over the zero shot baseline. This beats gpt-4o and babbage (61.23%), but loses to davinci (74.45%).
gpt-4o
A mixture of curiousity and gpt-4o finetuning going public at the perfect time led to finetuning gpt-4o, to the detriment of my wallet. The resulting model gets 71.37%, nearly matching the davinci completion model.
davinci
For completeness, I also tried finetuning the davinci completion model with just the PGN: move pairs, seeing a modest improvement.
Finetuning Results
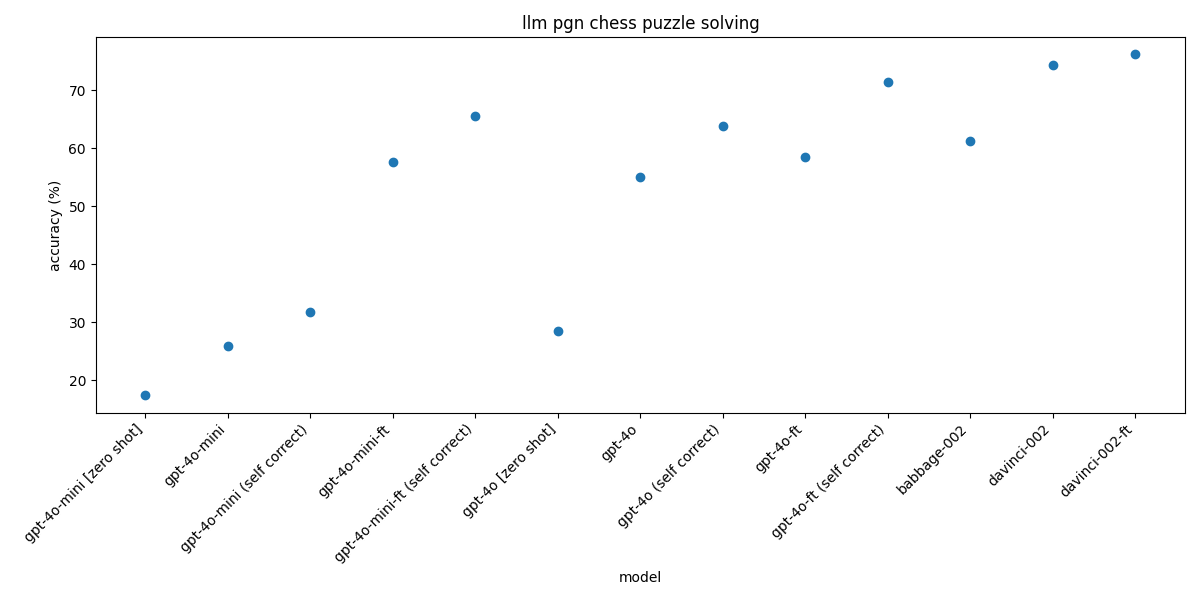
Completion models
| Model | Accuracy |
|---|
| babbage-002 | 61.23% |
| davinci-002 | 74.45% |
| davinci-002 finetune | 76.21% |
Chat models + DSPy
| Model | Accuracy |
|---|
| gpt-4o-mini [zero shot] | 17.4% |
| gpt-4o-mini | 25.99% |
| gpt-4o-mini [SELF CORRECT 3 tries max] | 31.72% |
| gpt-4o-mini finetune | 57.71% |
| gpt-4o-mini finetune [SELF CORRECT 3 tries max] | 65.64% |
| gpt-4o [zero shot] | 28.44 |
| gpt-4o | 55.07% |
| gpt-4o [SELF CORRECT 3 tries max] | 63.88% |
| gpt-4o finetune | 58.59% |
| gpt-4o finetune [SELF CORRECT 3 tries max] | 71.37% |
Notes
I asked Claude for some takeaways:
- The combination of prompt engineering and fine-tuning yields the best results, with the fine-tuned gpt-4o-mini model outperforming even gpt-4o in few-shot settings.
- The synergy between these approaches suggests that they address different aspects of model performance.
- Smaller, fine-tuned models can compete with larger models in specific tasks, offering potential efficiency gains.
TL;DR
First use DSPy with a cheap model to get a really good prompt, then use the optimized prompt with a strong model to create a finetuning example dataset. Finetuning on this dataset can make the performance of the cheap model competetive with the expensive teacher model.
comment on X
Play gpt-4o-mini